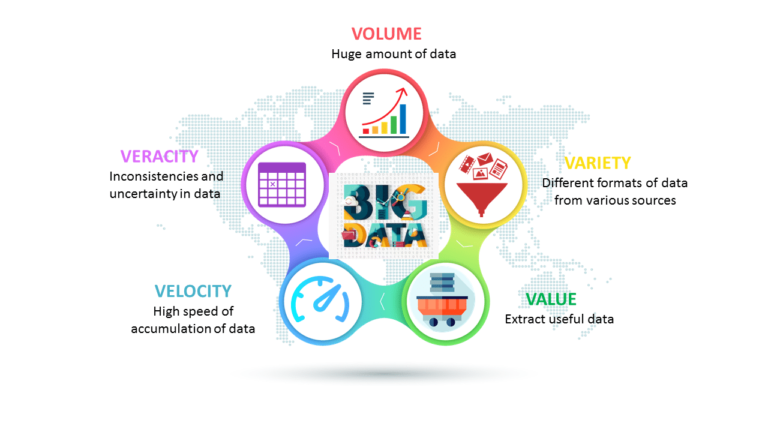
5 V’s of Big Data
23 March,2021
Over time, with the advancement of concepts in Big Data, the 3 V’s present became 5 V’s of Big Data. At
present, some have defined 6 V’s and 7 V’s as well, but here we will know more about the primary 5 terms
associated with Big Data.
It was in 2001 when an analytics firm Gartner (earlier known as MetaGroup) introduced to the world of Data Scientists and analysts the concept of 3 V’s that included: Volume, Velocity, and Variety only. But over the time, growth of data saw exponential changes and with these, two new Vs –Value and Veracity- have been added by Gartner to the data processing concepts.

The definition says, “It is the speed at which the data is generated, collected, and analyzed.” Big Data flows in from various sources around the world like computers, machines, social media, phones, websites, etc. Now, this data should also be captured as close to real-time as possible, making the right data available at the right time. That speed at which these data can be accessed makes an impact on various decisions including businesses and MNCs. Fact: On average, Google now processes more than 40,000 searches EVERY second (3.5 billion searches per day)!
Big data volume defines the ‘amount’ of data that is produced. The value of data is also dependent on the size of the data. To determine the value of data, the size of data plays a very crucial role. If the volume of data is very large then it is considered as ‘Big Data’. This means whether a particular data can be considered as Big Data or not, is dependent upon the volume of data. Data generated today from various sources are in different formats – structured and unstructured. Data is being produced in such large chunks, it has become tough for enterprises to store and process it using conventional methods of business intelligence and analytics. Enterprises must implement modern business intelligence tools to effectively capture, store and process such an unprecedented amount of data in real-time.
Variety of data are generally classified into structured, semi-structured, and unstructured. Now, what is the difference between all of them? Structured data means the data which are organized. They refer to the data that has defined the length and format of data. Semi-Structured data is semi-organized data. It is generally a form of data that does not conform to the formal structure of data. Log files are examples of this type of data. Unstructured data, as you can guess is unorganized data and doesn’t conform with the traditional data formats. Data generated via digital and social media (images, videos, tweets, etc.) can be classified as unstructured data. Most of the data that is generated is usually unstructured.
Also called validity, refers to the assurance of credibility and quality of the data that is gathered. Veracity can answer a lot of questions like “Is the data reliable?”, “Can companies conclude based on this data?”, “Should we make changes based on them?” Since a huge amount of data is generated every day, it is not always guaranteed that it might be useful and accurate for use. Hence, when processing big data sets, the validity of the data must be checked before proceeding with processing.
Of all the data you collect, it is of no use if it does not add any value to the company. The data will become trash if no insights can be garnered from it. This is where big data analytics(BDA) comes into the picture. While many companies have invested in establishing data aggregation and storage infrastructure in their organizations, they fail to understand that the aggregation of data doesn’t equal value addition. What you do with the collected data is what matters. With the help of advanced data analytics, useful insights can be derived from the collected data. These insights, in turn, are what add value to the decision-making process.